Submit an article
Submit an article
Articles
- Page Path
- HOME > J Korean Acad Nurs > Volume 55(4); 2025 > Article
-
Research Paper
- Development of a predictive model for exclusive breastfeeding at 3 months using machine learning : a secondary analysis of a cross-sectional survey
-
Hyun Kyoung Kim

-
Journal of Korean Academy of Nursing 2025;55(4):519-527.
DOI: https://doi.org/10.4040/jkan.25086
Published online: October 28, 2025
Department of Nursing, Kongju National University, Gongju, Korea
- Corresponding author: Hyun Kyoung Kim Department of Nursing, Kongju National University, 56 Gongjudaehak-ro, Gongju 32588, Korea E-mail: hkk@kongju.ac.kr
• Received: June 23, 2025 • Revised: September 2, 2025 • Accepted: September 2, 2025
© 2025 Korean Society of Nursing Science
This is an Open Access article distributed under the terms of the Creative Commons Attribution NoDerivs License (http://creativecommons.org/licenses/by-nd/4.0) If the original work is properly cited and retained without any modification or reproduction, it can be used and re-distributed in any format and medium.
- 2,652 Views
- 217 Download
Abstract
-
Purpose
- This study aimed to develop a machine learning model to predict exclusive breastfeeding during the first 3 months after birth and to explore factors affecting breastfeeding outcomes.
-
Methods
- Data from 2,579 participants in the Korean Early Childhood Education & Care Panel between March 1 and June 3, 2025 were analyzed using Python version 3.12.8 and Colab. The dataset was split into training and testing sets at an 80:20 ratio, and five classifiers (random forest, logistic regression, decision tree, AdaBoost, and XGBoost) were trained and evaluated using multiple performance metrics and feature importance analysis.
-
Results
- The confusion matrix of the random forest classifier model demonstrated strong performance, with a precision of 86.6%, accuracy of 84.8%, recall of 96.8%, F1-score of 91.9%, and an area under the curve of 86.0%. Twenty-one features were analyzed, from which feeding plan, breastfeeding at 1 month, marriage period, maternal prenatal weight, self-respect, alcohol consumption, grit, value placed on children, maternal age, and depression emerged as important predictors of exclusive breastfeeding in the first 3 months.
-
Discussion
- A robust model was developed to predict exclusive breastfeeding that identified feeding planning and breastfeeding at 1 month as the most influential predictors. The model could be implemented in clinical and community settings to guide tailored breastfeeding support strategies, coupled with the integration of maternal self-respect, grit, and the value placed on children in counseling programs to promote exclusive breastfeeding.
Introduction
Methods
1) Label: exclusive breastfeeding
2) Features
(1) Self-respect
(2) Grit
(3) Value placed on children
(4) Depression
(5) General and obstetric characteristics
Results
Discussion
Conclusion
-
Conflicts of Interest
Hyun Kyoung Kim is member of the editorial board of the Journal of Korean Academy of Nursing. However, she was not involved in the editorial handling, peer review, or decision-making process for this manuscript.
-
Acknowledgements
None.
-
Funding
This work was supported by the research grant of Kongju National University in 2025 and the National Research Foundation of Korea (NRF) Grant funded by the Korea government (MIST) (No. RS-2023-00239284).
-
Data Sharing Statement
Please contact the corresponding author for data availability.
-
Supplementary Data
Supplementary data to this article can be found online at https://doi.org/10.4040/jkan.25086.
Supplementary Figure 1. Visualization of the model using a decision tree classifier. EBF, exclusive breastfeeding.
-
Author Contributions
HKK participated in the conception, design of the study, the acquisition of data, drafted the first and final manuscript and funding acquisition.
Article Information
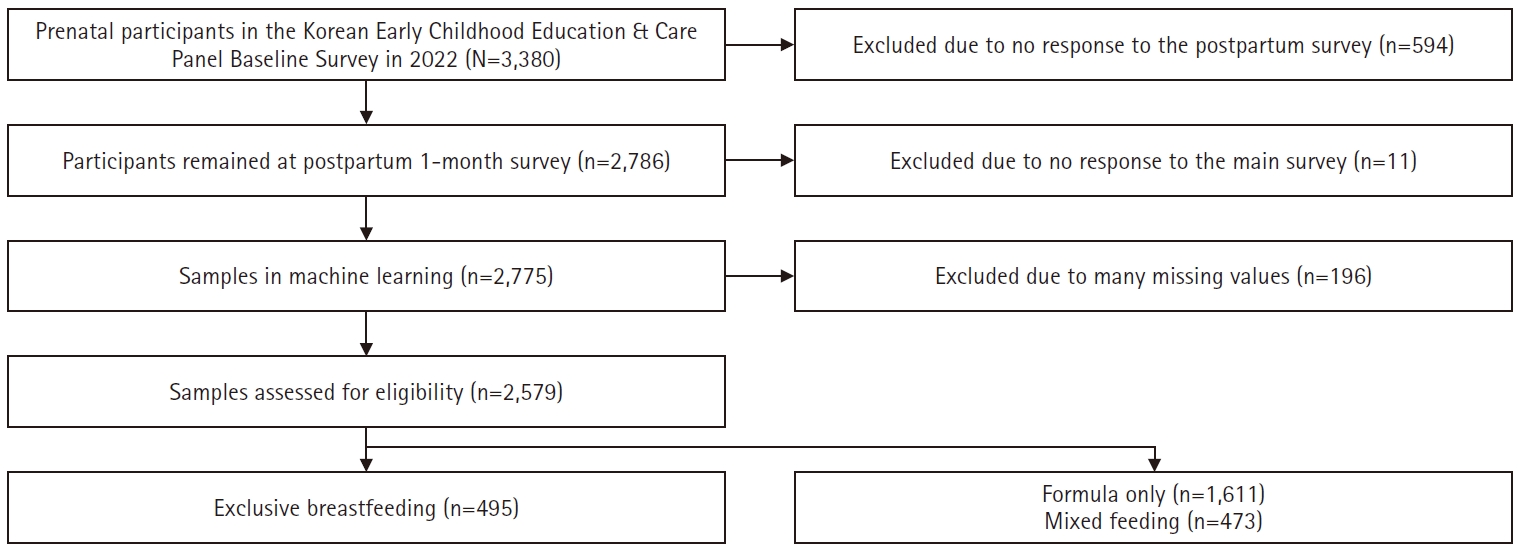
Table 1.Characteristics of datasets (N=2,579)
Table 2.Comparison of the performance of machine learning models (N=2,579)
Table 3.Top 10 feature importance values from the random forest (N=2,579)
- 1. Korea Institute for Health and Social Affairs. The 2024 National Family and Fertility Survey [Internet]. Korea Institute for Health and Social Affairs; 2024 [cited 2025 Mar 9]. Available from: https://www.kihasa.re.kr/publish/report/research/view?seq=68528
- 2. US Department of Health and Human Services. Healthy People 2030: increase the proportion of infants who are breastfed exclusively through age 6 months-MICH‑15 [Internet]. US Department of Health and Human Services; 2021 [cited 2025 Mar 9]. Available from: https://odphp.health.gov/healthypeople/objectives-and-data/browse-objectives/infants/increase-proportion-infants-who-are-breastfed-exclusively-through-age-6-months-mich-15
- 3. Meek JY, Noble L; Section on Breastfeeding. Policy statement: breastfeeding and the use of human milk. Pediatrics. 2022;150(1):e2022057988. https://doi.org/10.1542/peds.2022-057988ArticlePubMed
- 4. Davie P, Chilcot J, Chang YS, Norton S, Hughes LD, Bick D. Effectiveness of social-psychological interventions at promoting breastfeeding initiation, duration and exclusivity: a systematic review and meta-analysis. Health Psychol Rev. 2020;14(4):449-485. https://doi.org/10.1080/17437199.2019.1630293ArticlePubMed
- 5. Gianni ML, Bettinelli ME, Manfra P, Sorrentino G, Bezze E, Plevani L, et al. Breastfeeding difficulties and risk for early breastfeeding cessation. Nutrients. 2019;11(10):2266. https://doi.org/10.3390/nu11102266ArticlePubMedPMC
- 6. Zhang J, Li Y, Zhu L, Shang Y, Yan Q. The effectiveness of online breastfeeding education and support program on mothers of preterm infants: a quasi-experimental study. Midwifery. 2024;130:103924. https://doi.org/10.1016/j.midw.2024.103924ArticlePubMed
- 7. Wu HL, Lu DF, Tsay PK. Rooming-in and breastfeeding duration in first-time mothers in a modern postpartum care center. Int J Environ Res Public Health. 2022;19(18):11790. https://doi.org/10.3390/ijerph191811790ArticlePubMedPMC
- 8. Bronfenbrenner U. The ecological model of human development in international encyclopedia of education. 2nd ed. Elsevier; 1994.
- 9. Açikgöz A, Çakirli M, Şahin BM, Çelik Ö. Predicting mothers’ exclusive breastfeeding for the first 6 months: interface creation study using machine learning technique. J Eval Clin Pract. 2024;30(6):1000-1007. https://doi.org/10.1111/jep.14009ArticlePubMed
- 10. Liu Y, Xiang J, Yan P, Liu Y, Chen P, Song Y, et al. Trajectory of breastfeeding among Chinese women and risk prediction models based on machine learning: a cohort study. BMC Pregnancy Childbirth. 2024;24(1):858. https://doi.org/10.1186/s12884-024-07010-zArticlePubMedPMC
- 11. Hastie T, Tibshirani R, Friedman J. The elements of statistical learning: data mining, inference, and prediction. 2nd ed. Springer; 2009.
- 12. Korea Institute of Child Care and Education. Korean Early Childhood Education & Care Panel (K-ECEC-P) 2022 survey [Internet]. Korea Institute of Child Care and Education; 2024 [cited 2025 Mar 1]. Available from: https://panel.kicce.re.kr/kececp/module/rawDataManage/index.do?menu_idx=52
- 13. Korea Institute of Child Care and Education. Scale profile of self-respect for parents [Internet]. Korea Institute of Child Care and Education; 2024 [cited 2025 Feb 21]. Available from: https://panel.kicce.re.kr/pskc/board/view.do?menu_idx=42&board_idx=44530&manage_idx=161
- 14. Rosenberg M. Society and the adolescent self-image [Internet]. Wesleyan University Press; 1989 [cited 2023 Jun 5]. Available from: https://socy.umd.edu/about-us/using-rosenberg-self-esteem-scale
- 15. Duckworth AL, Quinn PD. Development and validation of the short grit scale (grit-s). J Pers Assess. 2009;91(2):166-174. https://doi.org/10.1080/00223890802634290ArticlePubMed
- 16. Kim HM, Hwang MH. Validation of the Korean grit scale for children. J Educ. 2015;35(3):63-74. https://doi.org/10.25020/je.2015.35.3.63Article
- 17. Lee SS, Jung YS, Kim HK, Choi EY, Park SK, Jo NH, et al. 2005 National Survey on Dynamics of Marriage and Fertility [Internet]. Korea Institute for Health and Social Affairs; 2005 [cited 2025 Feb 23]. Available from: https://repository.kihasa.re.kr/en/bitstream/201002/608/1/%ec%97%b0%ea%b5%ac%eb%b3%b4%ea%b3%a0%ec%84%9c%202005-30-1.pdf
- 18. Han K, Kim M, Park JM. The Edinburgh Postnatal Depression Scale, Korean version: reliability and validity. J Korean Soc Biol Ther Psychiatry. 2004;10(2):201-207.
- 19. Cox JL, Holden JM, Sagovsky R. Detection of postnatal depression: development of the 10-item Edinburgh Postnatal Depression Scale. Br J Psychiatry. 1987;150:782-786. https://doi.org/10.1192/bjp.150.6.782ArticlePubMed
- 20. Austin PC, White IR, Lee DS, van Buuren S. Missing data in clinical research: a tutorial on multiple imputation. Can J Cardiol. 2021;37(9):1322-1331. https://doi.org/10.1016/j.cjca.2020.11.010ArticlePubMed
- 21. Krishnan R, Rajpurkar P, Topol EJ. Self-supervised learning in medicine and healthcare. Nat Biomed Eng. 2022;6(12):1346-1352. https://doi.org/10.1038/s41551-022-00914-1ArticlePubMed
- 22. Sagu A, Gill NS. Machine learning decision tree classifier and logistic regression model. Int J Adv Trends Comput Sci Eng. 2020;9(1.4):163-166. https://doi.org/10.30534/ijatcse/2020/2491.42020Article
- 23. Salman HA, Kalakech A, Steit A. Random forest algorithm overview. Babylonian J Mach Learn. 2024;2024:69-79. https://doi.org/10.58496/BJML/2024/007Article
- 24. Choi ES, Lee JS, Lee H, Lee KS, Ahn KH. Association between breastfeeding duration and diabetes mellitus in menopausal women: a machine-learning analysis using population-based retrospective study. Int Breastfeed J. 2024;19(1):33. https://doi.org/10.1186/s13006-024-00642-zArticlePubMedPMC
- 25. Oliver-Roig A, Rico-Juan JR, Richart-Martínez M, Cabrero-García J. Predicting exclusive breastfeeding in maternity wards using machine learning techniques. Comput Methods Programs Biomed. 2022;221:106837. https://doi.org/10.1016/j.cmpb.2022.106837ArticlePubMed
- 26. Walle AD, Abebe Gebreegziabher Z, Ngusie HS, Kassie SY, Lambebo A, Zekarias F, et al. Prediction of delayed breastfeeding initiation among mothers having children less than 2 months of age in East Africa: application of machine learning algorithms. Front Public Health. 2024;12:1413090. https://doi.org/10.3389/fpubh.2024.1413090ArticlePubMedPMC
- 27. Huh Y, Kim YN, Kim YS. Trends and determinants in breastfeeding among Korean women: a nationwide population-based study. Int J Environ Res Public Health. 2021;18(24):13279. https://doi.org/10.3390/ijerph182413279ArticlePubMedPMC
- 28. Dalrymple KV, Briley AL, Tydeman FA, Seed PT, Singh CM, Flynn AC, et al. Breastfeeding behaviours in women with obesity; associations with weight retention and the serum metabolome: a secondary analysis of UPBEAT. Int J Obes (Lond). 2024;48(10):1472-1480. https://doi.org/10.1038/s41366-024-01576-6ArticlePubMedPMC
- 29. Washio Y, Raines AL, Lv M, Pei S, Taylor SN, Zhang Z. The association of maternal smoking and drinking changes during pregnancy and postpartum breastfeeding pattern and duration. Breastfeed Med. 2023;18(6):449-461. https://doi.org/10.1089/bfm.2022.0130ArticlePubMedPMC
- 30. Mercan Y, Tari Selcuk K. Association between postpartum depression level, social support level and breastfeeding attitude and breastfeeding self-efficacy in early postpartum women. PLoS One. 2021;16(4):e0249538. https://doi.org/10.1371/journal.pone.0249538ArticlePubMedPMC
- 31. Dehghani M, Kazemi A, Heidari Z, Mohammadi F. The relationship between women’s breastfeeding empowerment and conformity to feminine norms. BMC Pregnancy Childbirth. 2023;23(1):287. https://doi.org/10.1186/s12884-023-05628-zArticlePubMedPMC
- 32. Woods Barr A. “It needs to become a norm again and not make it feel like it’s something so foreign”: (re)normalizing and reclaiming breastfeeding in African American families. J Perinat Neonatal Nurs. 2025;39(2):118-128. https://doi.org/10.1097/JPN.0000000000000901ArticlePubMed
- 33. Kim CY, Smith NP, Teti DM. Associations between breastfeeding, maternal emotional availability, and infant-mother attachment: the role of coparenting. J Hum Lact. 2024;40(3):455-463. https://doi.org/10.1177/08903344241247207ArticlePubMedPMC
References
Figure & Data
REFERENCES
Citations
Citations to this article as recorded by 
 ePub Link
ePub Link Cite
CiteDevelopment of a predictive model for exclusive breastfeeding at 3 months using machine learning : a secondary analysis of a cross-sectional survey
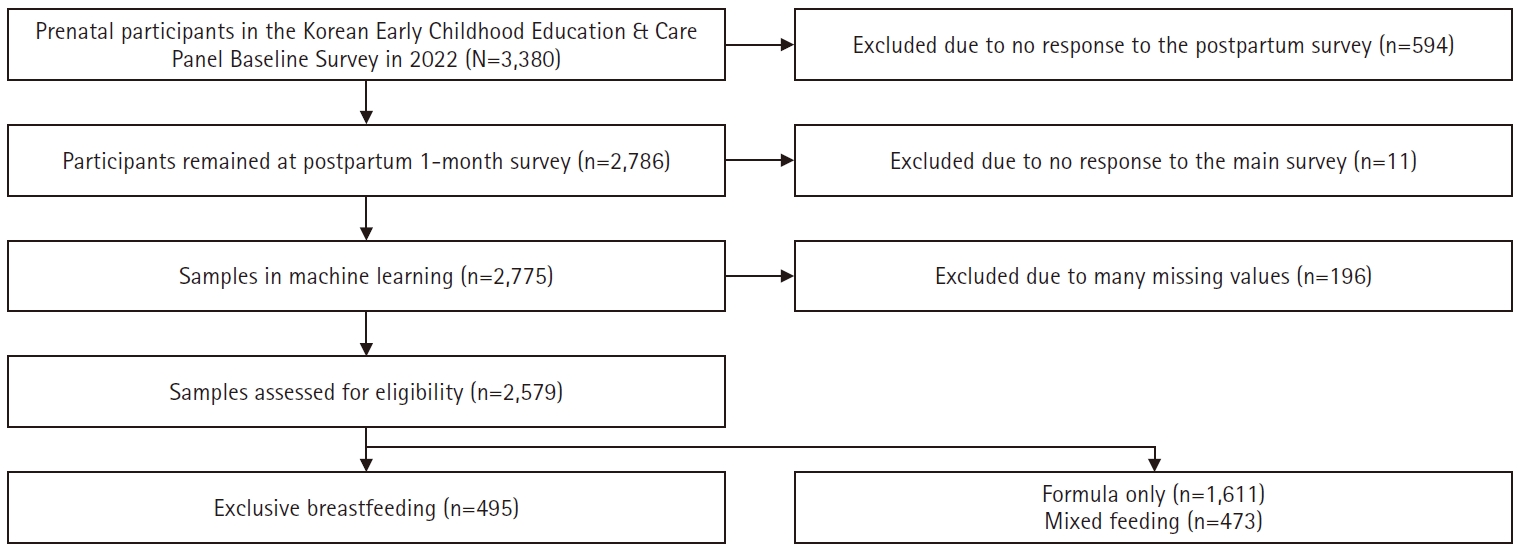
Fig. 1. Flow of study participants.
Fig. 1.
Development of a predictive model for exclusive breastfeeding at 3 months using machine learning : a secondary analysis of a cross-sectional survey
| Characteristic | Category | Value |
|---|---|---|
| Maternal age (yr) | 33.5±4.16 (17–49) | |
| Marriage period (mo) | 24.33±13.91 (6–62) | |
| Maternal prenatal weight (kg) | 68.05±12.17 (45–125) | |
| Employment status | Employed | 1,308 (50.7) |
| Unemployed | 1,271 (49.3) | |
| No. of children | 1.45±0.65 (1–4) | |
| Twin pregnancy | Yes | 131 (5.1) |
| No | 2,448 (94.9) | |
| Type of birth | Normal delivery | 997 (38.7) |
| Cesarean section | 1,582 (61.3) | |
| Alcohol consumption | Yes | 1,237 (48.0) |
| No | 1,342 (52.0) | |
| Smoking | Yes | 75 (2.9) |
| No | 2,504 (97.1) | |
| Use of rooming-in | Yes | 1,820 (70.6) |
| No | 759 (29.4) | |
| Time of first breastfeeding | ≤1 hr | 119 (4.6) |
| >1–24 hr | 627 (24.3) | |
| >24–48 hr | 537 (20.8) | |
| >48 hr–7 day | 925 (35.9) | |
| None | 371 (14.4) | |
| Skin contact with baby | Yes | 1,221 (47.3) |
| No | 1,358 (52.7) | |
| Use of nursery | Yes | 2,222 (86.2) |
| No | 357 (13.8) | |
| Use of babysitter | Yes | 1,346 (52.2) |
| No | 1,233 (47.8) | |
| Breastfeeding at 0 mo | Breastfeeding only | 635 (24.6) |
| Mixed | 1,602 (62.1) | |
| Formula only | 342 (13.3) | |
| Breastfeeding at 1 mo | Breastfeeding only | 600 (23.3) |
| Mixed | 1,171 (45.4) | |
| Formula only | 808 (31.3) | |
| Feeding plan | Yes | 625 (24.2) |
| No | 1,954 (75.8) | |
| Self-respect | 30.18±5.01(12–40) | |
| Grit | 22.26±4.25 (11–40) | |
| Value placed on children | 25.84±4.86 (9–40) | |
| Depression | 7.78±5.65 (0–29) | |
| Breastfeeding at 3 mo | EBF | 495 (19.2) |
| Non-EBF | 2,084 (80.8) |
| Model | Precision | Accuracy | Recall | F1-score | AUC-ROC |
|---|---|---|---|---|---|
| AdaBoost | 88.3 (87.1–89.6) | 82.4 (89.5–91.7) | 90.6 (89.5–91.7) | 89.6 (86.9–90.3) | 84.0 (82.6–85.4) |
| XGBoost | 87.5 (86.2–88.8) | 84.6 (83.2–86.0) | 93.6 (92.7–94.6) | 90.7 (88.5–92.9) | 86.0 (84.7–87.3) |
| Decision tree | 87.0 (85.7–88.3) | 73.5 (72.2–75.6) | 78.7 (77.1–80.3) | 82.5 (80.8–86.2) | 85.0 (83.6–86.4) |
| Random forest | 86.6 (85.3–87.9) | 84.8 (83.4–86.2) | 96.8 (96.1–97.5) | 91.9 (89.0–95.7) | 86.0 (84.7–87.3) |
| Logistic regression | 87.4 (86.1–88.7) | 83.6 (82.2–85.1) | 93.5 (92.6–94.5) | 86.7 (83.4–88.4) | 85.0 (83.6–86.4) |
| Feature | Absolute importance (95% CI) | Real value |
|---|---|---|
| Feeding plan | .12 (0.09–0.14) | 0.12 |
| Breastfeeding at 1 mo | .11 (0.09–0.13) | 0.11 |
| Marriage period | .06 (0.05–0.07) | –0.06 |
| Maternal prenatal weight | .06 (0.05–0.07) | –0.06 |
| Self-respect | .05 (0.05–0.06) | 0.05 |
| Alcohol consumption | .05 (0.04–0.07) | –0.05 |
| Grit | .05 (0.04–0.05) | 0.05 |
| Value placed on child | .05 (0.05–0.06) | 0.05 |
| Maternal age | .05 (0.04–0.05) | –0.05 |
| Depression | .04 (0.04–0.05) | –0.05 |
Table 1. Characteristics of datasets (N=2,579)
Values are presented as mean±standard deviation (minimum–maximum) or number (%). EBF, exclusive breastfeeding.
Table 2. Comparison of the performance of machine learning models (N=2,579)
Values are presented as % (95% confidence interval). F1-score, harmonic mean of precision and recall; AUC-ROC, area under the receiver operating characteristic curve.
Table 3. Top 10 feature importance values from the random forest (N=2,579)
CI, confidence interval.